海量数据就需要对应大数据技术去存储和处理它。
本文章主要介绍如何搭建大数据生态环境。
Quick Guide
现在搭建大数据环境有三种方式:
1.docker方式: 利用docker-compose一键编排部署
- 优点:一键部署,快捷方便
- 缺点:性能不高只适合测试环境或者学习
2.使用成熟的发行版本去部署:例如 CM(Cloudera Manager)+CDH(Cloudera’s Distribution Including Apache Hadoop)或者Ambari+HDP(Hortonworks Data Platform)
- 优点:集群安装部署和运维方便
- 缺点:屏蔽太多细节,妨碍对组件理解
3.使用开源版本:
- 优点: 完全开源免费,社区活跃, 文档、资料详实 ,
- 缺点: 集群安装部署复杂,需要编写大量配置文件,需要考虑组件之间的兼容性问题、版本匹配问题、冲突问题、编译问题等; 集群运维复杂,需要安装第三方软件辅助。
机器准备
- 1.准备多台物理机或者使用VM安装多台虚机
- 2.从官网下载centos系统包并安装
机器配置
如果是docker方式部署,就不需要经历这个步骤
- 0.修改服务器的ip地址
1 | vi /etc/sysconfig/network-scripts/ifcfg-eth0 |
例如:将准备好的三台服务器的IP地址分别设置成为如下:
- 第一台机器IP地址:192.168.52.100
- 第二台机器IP地址:192.168.52.110
- 第三台机器IP地址:192.168.52.120
第四台机器IP地址:192.168.52.130
1.关闭防火墙
1 | # centos 7 默认使用的是firewall,也可以使用iptables配置规则 |
- 2.关闭SELinux(所有节点)
1 | # 使用root用户登录四台服务器,执行以下命令关闭selinux |
- 3.修改主机名
1 | # 在不同机器上执行 |
- 4.更改主机名与IP地址映射
1 | vim /etc/hosts |
- 5.主机间ntp同步时间
1 | yum -y install ntpdate |
- 6.添加普通用户
1 | # 创建hadoop,并设置密码为 hadoop |
- 7.配置免密登录
1 | # 生成私钥和公钥,在/home/当前用户/.ssh目录下找到id_rsa(私钥)和id_rsa.pub(公钥) |
- 8.定义统一目录
1 | mkdir -p /hadoop/soft # 软件压缩包存放目录 |
- 9.安装java
1 | # 从官网下载jdk包,解压到目录 |
- 10.在root用户下重启
1 | reoot -h now |
Docker 部署
不少公司把所有的 大数据组件都做成了 docker image ,可以直接通过 docker-compose 一键按照,具体看一下参考下面的教程:
CM + CDH 部署
- CM:Cloudera Manager,Cloudera公司编写的一个CDH的管理后台,类似各CMS的管理后台。
CDH:Cloudera’s distribution,including Apache Hadoop,Cloudera公司制作的一个Hadoop发行版,集成了Hadoop及Hive等与Hadoop关系紧密的工具。
1.下载
- 根据操作系统从CM bin文件下载对应版本
- 根据操作系统从[CM rpm包]http://archive.cloudera.com/cm5/redhat/6/x86_64/cm/)下载对应版本
- 根据操作系统从CDH下载对应版本的manifest.json、.parcel和.sha1文件
2.上传介质到master,上传目录为/hadoop/soft,并解压
1 | tar -zxvf cm5.5.1.tar.gz |
- 3.各个节点配置本地yum源(master)
1 | cd /etc/yum.repos.d |
添加下面内容
1 | [cloudera-manager] |
- 4.启动http服务
1 | service httpd status # 查看服务状态 |
5.验证本地yum源
- 将上一步baseurl地址粘贴到浏览器
- 确认是否能正常访问到已经上传安装文件的机器的安装文件目录。
6.运行CM安装
1 | # 赋予bin文件执行权限 |
7.验证CM安装是否完成
- 使用命令查看服务状态:service cloudera-scm-server status
- 点击 管理界面(http://192.168.52.100:7180/cmf) 登陆,用户名和密码都为admin
8.修正参数
1 | echo 0 > /proc/sys/vm/swappiness |
9.开始安装
- 1.接受许可
- 2.选择相应的版本
- 3.选择主机:搜索主机,也可以自己输ip
- 4.选择存储库:使用Parcel,远程Parcel 存储库URL指定安装源(本地源)
- 5.勾选JDK
- 6.填写用户(hadoop)密码
- 7.开始安装
- 8.自定义添加服务
- 9.安装角色
- 10.数据库选择:建议使用默认数据库。以后可以进行修改。
- 11.指定数据目录
10.排错
- 1.完成以上,说明集群已经安装成功,其他问题需要在后续过程调试。页面显示红色不等于服务没有安装成功,验证参数没有满足默认而已。
- 2.关闭时钟同步
- 3.验证安装:例如 到安装HDFS角色的服务器上任意目录执行如下命令(hadoop fs -ls /),能正常执行即代表功能可用
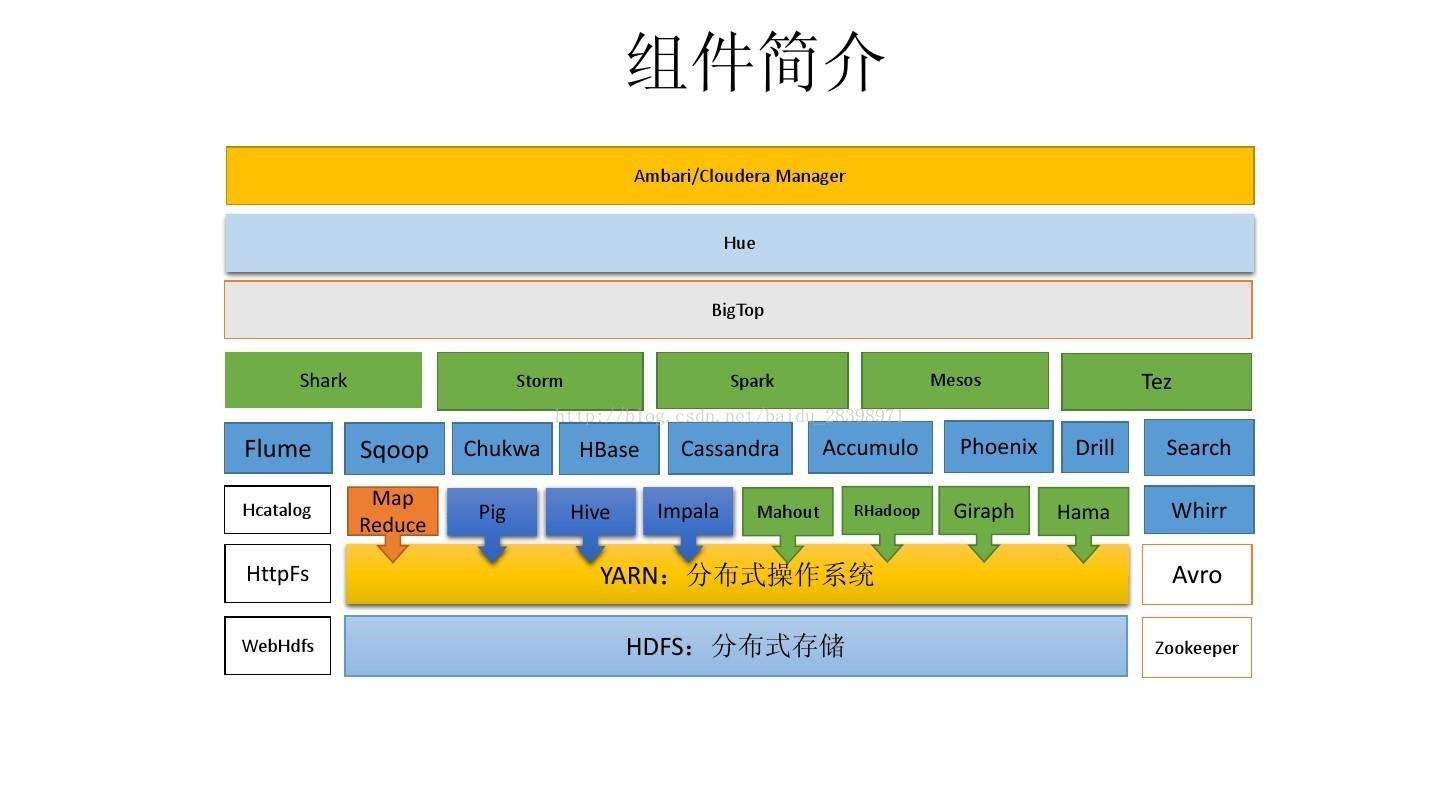
开源版本部署
从下图可以知道,使用开源版本部署比较麻烦,组件比较多,后面就一章一章慢慢说。