随着海量数据增加,需要大数据技术去存储和处理它。Hadoop是大数据技术的基础,对Hadoop基础知识的掌握的扎实程度,会决定在大数据技术道路上走多远。
本文章主要介绍Hadoop的基础知识。
Quick Guide
起源
Google 遇到两个问题 大量的网页日益增加怎么存储 和 搜索算法,提出了三大理论(GFS 文件存储、Map-Reduce 计算、BigTable)来解决这个问题,受到启发的Doug Cutting等人开始尝试实现MapReduce计算框架,并将它与NDFS(Nutch Distributed File System)结合,用以支持Nutch引擎的主要算法。
由于NDFS和MapReduce在Nutch引擎中有着良好的应用,所以它们于2006年2月被分离出来,成为一套完整而独立的软件,并被命名为Hadoop。
Hadoop
Apache Hadoop 是一个开源分布式计算软件框架,允许使用 简单的编程模型 在 跨计算机集群 的 分布式环境 中存储和处理大数据。
- 数据分布在多台机器,单份数据复制到多个节点
- 尽量地将任务分配到离数据最近的机器上运行(网络IO速度 << 本地磁盘IO速度)
- 使用串行IO取代随机IO,一般数据写入后不再修改(传输时间 << 寻道时间)
优点
- 高可靠性:冗余副本策略、机架感知策略、心跳机制、安全模式、校验和、回收站、元数据保护和快照机制等设计保证可靠性。例如冗余副本策略,自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快 。
- 低成本:开源的,只需要一般的商用硬件。
生态系统和组件
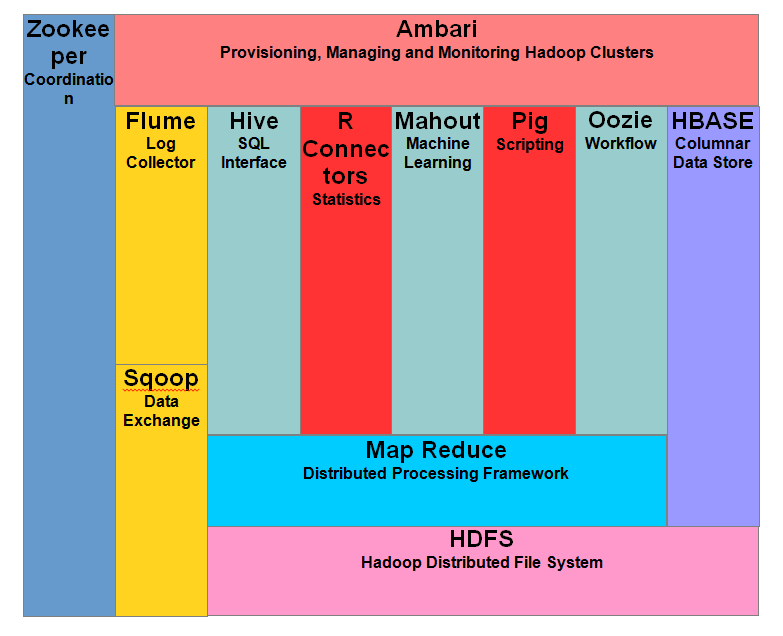
Hadoop架构
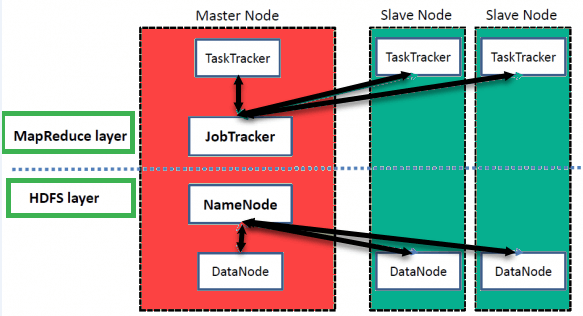
- 主节点:主节点允许您使用Hadoop MapReduce进行数据并行处理。
- 从节点:从节点是Hadoop集群中的其他计算机,可让您存储数据以进行复杂的计算。此外,所有从属节点都随附有Task Tracker和一个DataNode。这使您可以分别与NameNode和Job Tracker同步进程。
- NameNode:NameNode表示名称空间中使用的每个文件和目录
- 数据节点:DataNode可帮助您管理HDFS节点的状态,并允许您与块进行交互
Hadoop组成
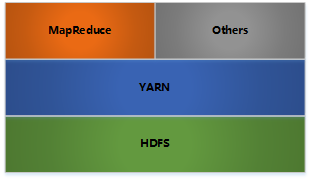
MapReduce: 分布式计算
HDFS: 分布式文件存储
YARN: 分布式资源管理
Others: 利用YARN的资源管理功能实现其他的数据处理方式
HDFS
- Block数据块
- 基本存储单位,一般大小为64M(注:配置大的块 )
- 减少搜寻时间,一般硬盘传输速率比寻道时间要快,大的块可以减少寻道时间;
- 减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;
- 对数据块进行读写,减少建立网络的连接成本;
- 一个大文件会被拆分成一个个的块,然后存储于不同的机器。如果一个文件少于Block大小,那么实际占用的空间为其文件的大小
- 基本的读写单位,类似于磁盘的页,每次都是读写一个块
- 每个块都会被复制到多台机器,默认复制3份
- 基本存储单位,一般大小为64M(注:配置大的块 )
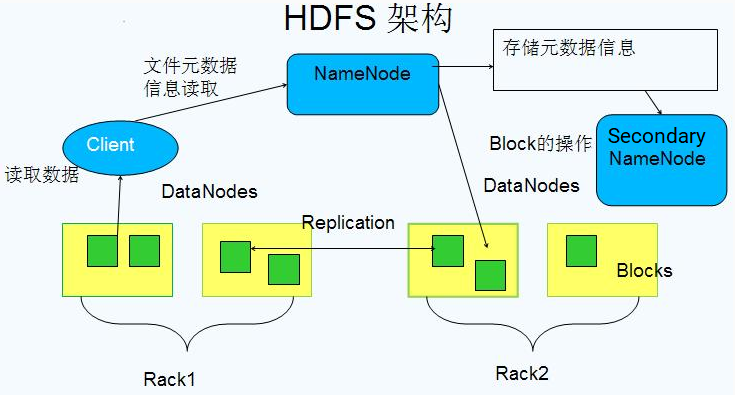
- NameNode
- 存储文件的metadata,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小
- 一个Block在NameNode中对应一条记录(一般一个block占用150字节),如果是大量的小文件,会消耗大量内存。同时map task的数量是由splits来决定的,所以用MapReduce处理大量的小文件时,就会产生过多的map task,线程管理开销将会增加作业时间。处理大量小文件的速度远远小于处理同等大小的大文件的速度。因此Hadoop建议存储大文件
- 数据会定时保存到本地磁盘,但不保存block的位置信息,而是由DataNode注册时上报和运行时维护(NameNode中与DataNode相关的信息并不保存到NameNode的文件系统中,而是NameNode每次重启后,动态重建)
- NameNode失效则整个HDFS都失效了,所以要保证NameNode的可用性
- Secondary NameNode
- 定时与NameNode进行同步(定期合并文件系统镜像和编辑日志,然后把合并后的传给NameNode,替换其镜像,并清空编辑日志,类似于CheckPoint机制),但NameNode失效后仍需要手工将其设置成主机
- DataNode
- 保存具体的block数据
- 负责数据的读写操作和复制操作
- DataNode启动时会向NameNode报告当前存储的数据块信息,后续也会定时报告修改信息
- DataNode之间会进行通信,复制数据块,保证数据的冗余性
YARN
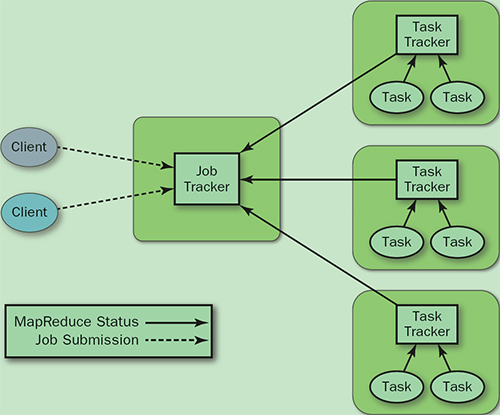
旧的MapReduce架构:存在单点和资源利用率问题
- JobTracker: 负责资源管理,跟踪资源消耗和可用性,作业生命周期管理(调度作业任务,跟踪进度,为任务提供容错)
- TaskTracker: 加载或关闭任务,定时报告任务状态
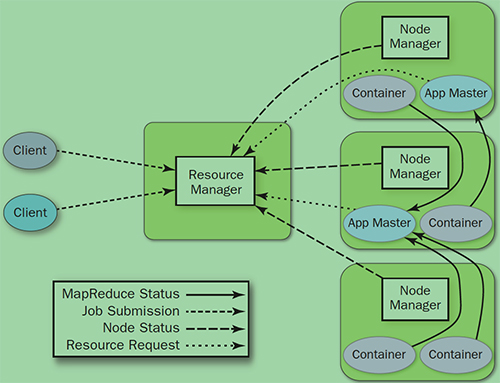
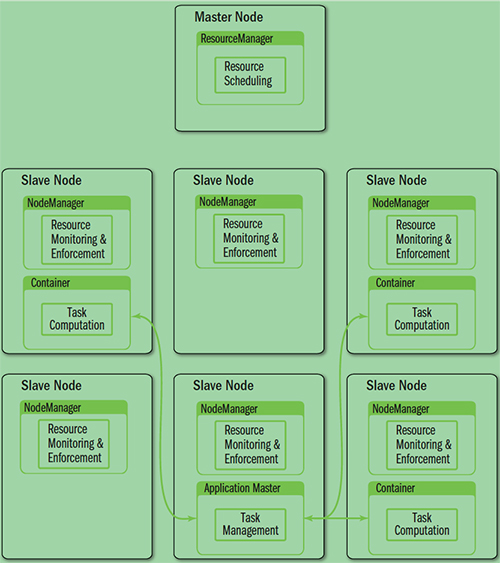
YARN就是将JobTracker的职责进行拆分,将资源管理和任务调度监控拆分成独立的进程:
- ResourceManager: 全局资源管理和任务调度
- NodeManager: 单个节点的资源管理和监控
- ApplicationMaster: 单个作业的资源管理和任务监控
- Container: 资源申请的单位和任务运行的容器
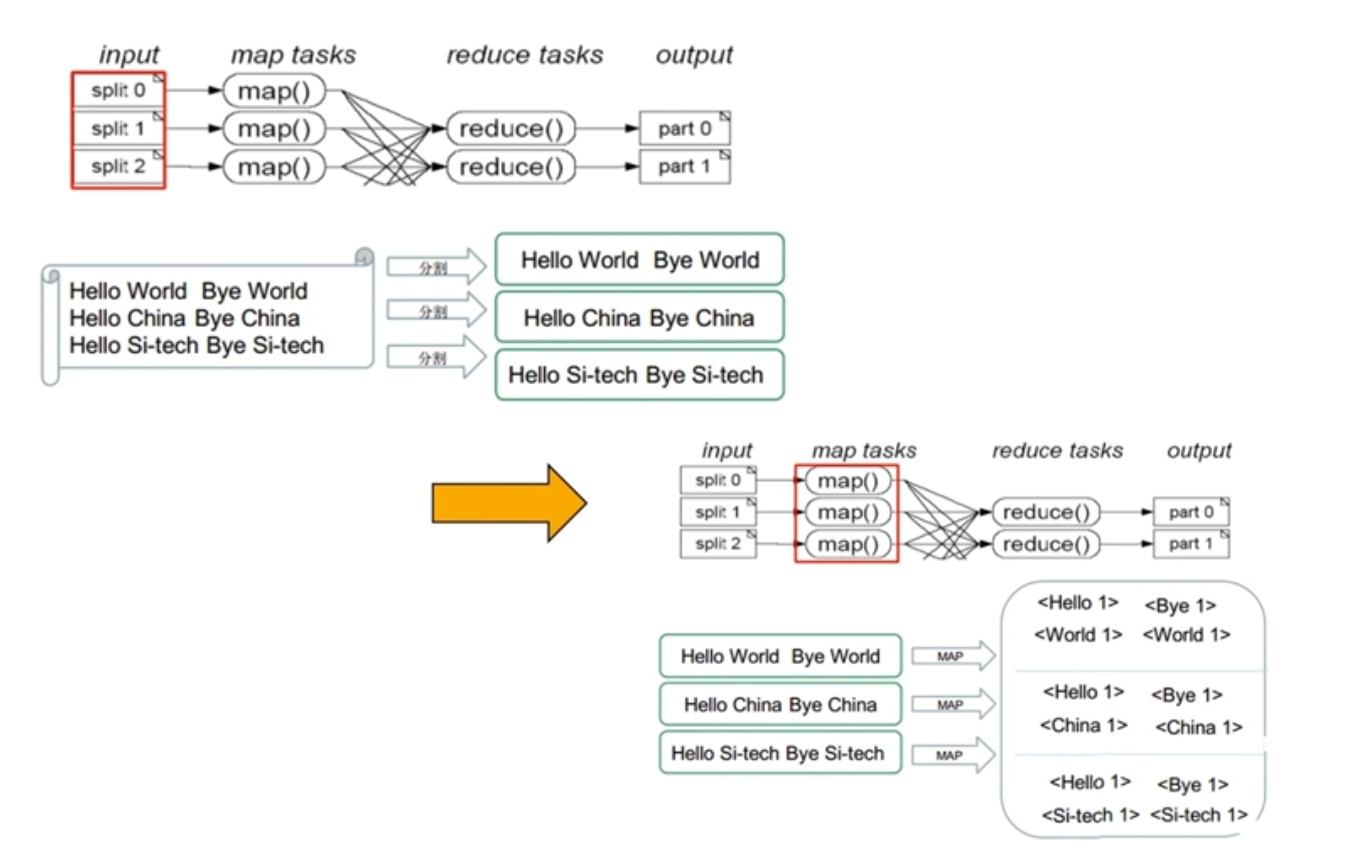
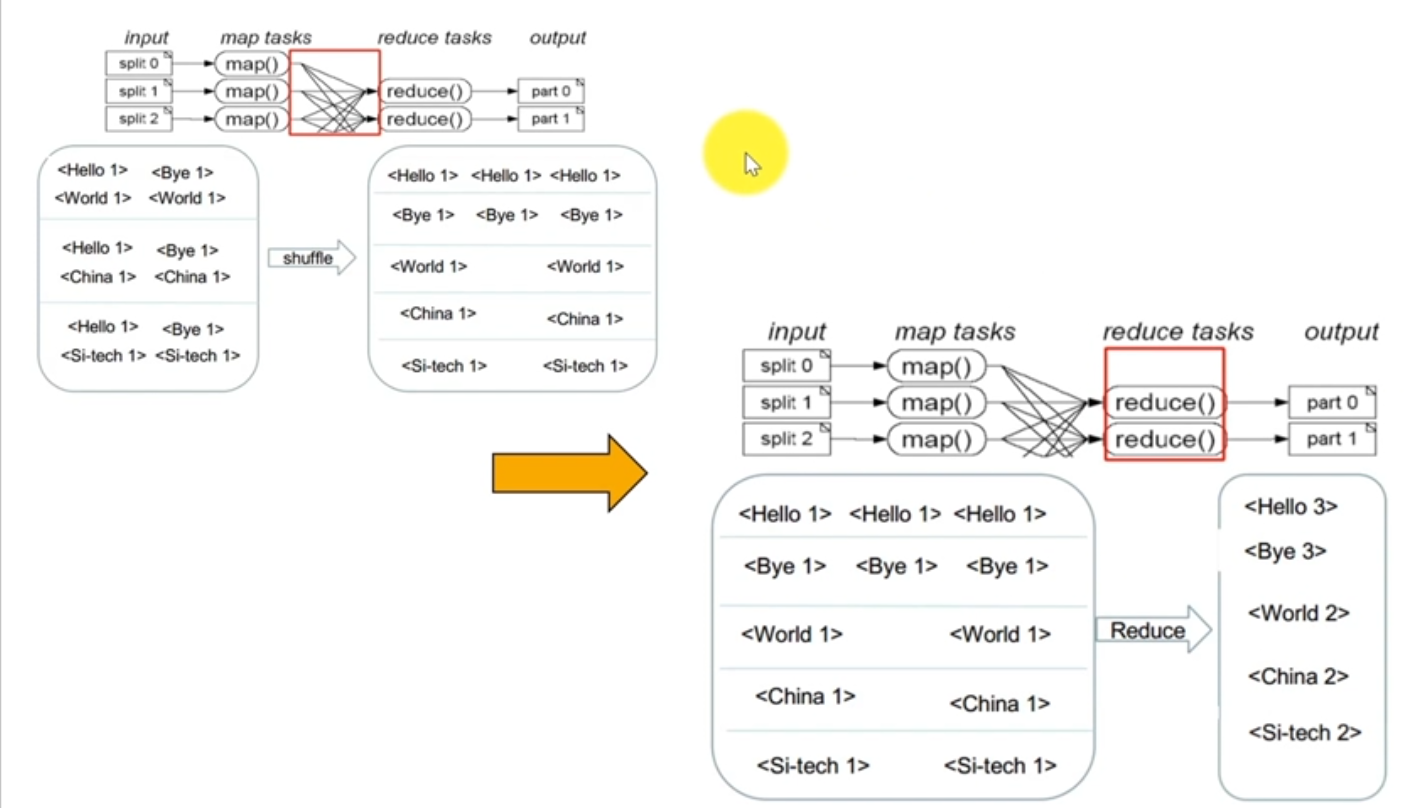
MapReduce
MapReduce主要是先读取文件数据,然后进行Map处理,接着Reduce处理,最后把处理结果写到文件中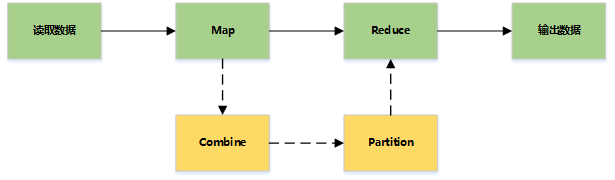
More info: Hadoop