本文章主要介绍在centos环境下如何安装Hadoop。
Quick Guide
下载并安装Hadoop
- 1.使用以下命令添加Hadoop系统用户
1
2sudo addgroup hadoop # 新建用户组
sudo adduser --ingroup hadoop hadoop # 新建用户
注意:出现这个报错”hadoop is not in the sudoers file. This incident will be reported.”,可以通过以root用户身份登录解决此错误
- 2.配置SSH
1
2
3
4su - hadoop # 切换用户
ssh-keygen -t rsa -P "" # 创建一个新密钥
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys # 启用密钥
ssh localhost # 测试是否可用
注意:出现 openssh-server没安装的错误,请使用下面命令安装1
yum openssh-server
3.下载Hadoop
3.1 点击Hadoop链接,再点击镜像地址
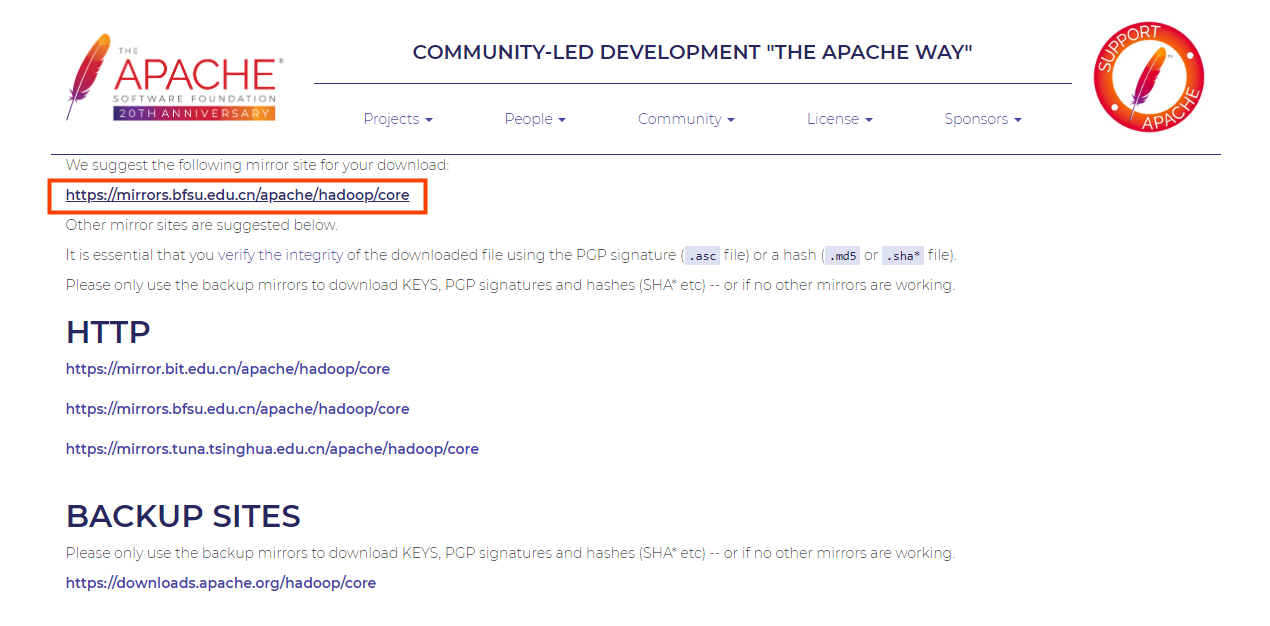
3.2 选择稳定版本
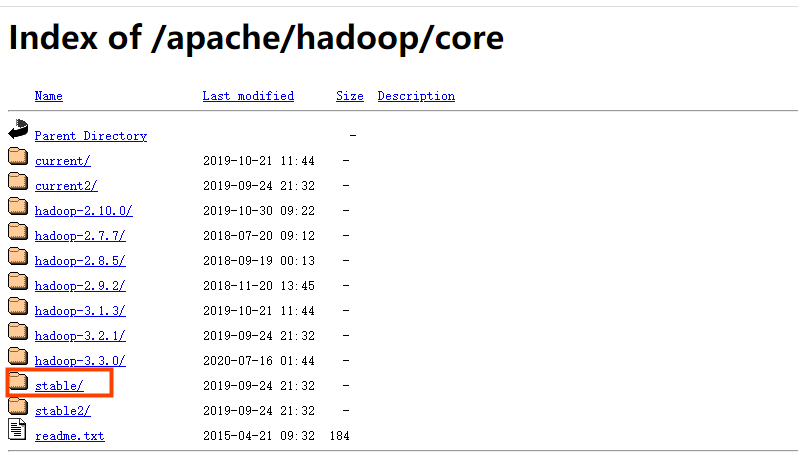
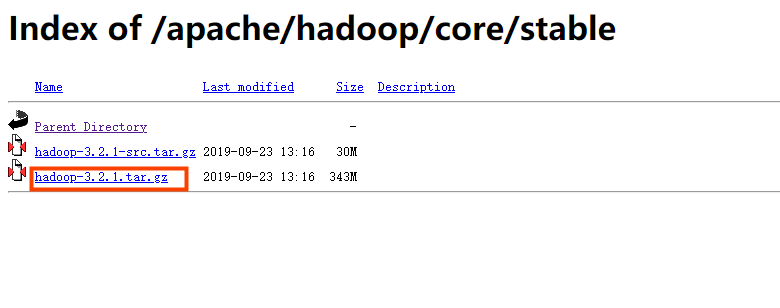
3.3 选择tar.gz文件(文件名没有’src’)
4.放到服务器解压
1
2
3
4sudo tar xzf hadoop-3.2.1.tar.gz -C /hadoop/install # 解压
cd /hadoop/install
sudo mv hadoop-3.2.1 hadoop # 修改文件名
sudo chown -R hadoop:hadoop hadoop # 目录增加用户权限
配置Hadoop
配置环境变量
1 | export HADOOP_HOME=<Hadoop的安装路径> # 设置HADOOP_HOME |
配置 HDFS
配置环境变量
在 $HADOOP_HOME/etc/hadoop/hadoop-env.sh 设置 JAVA_HOME
配置前: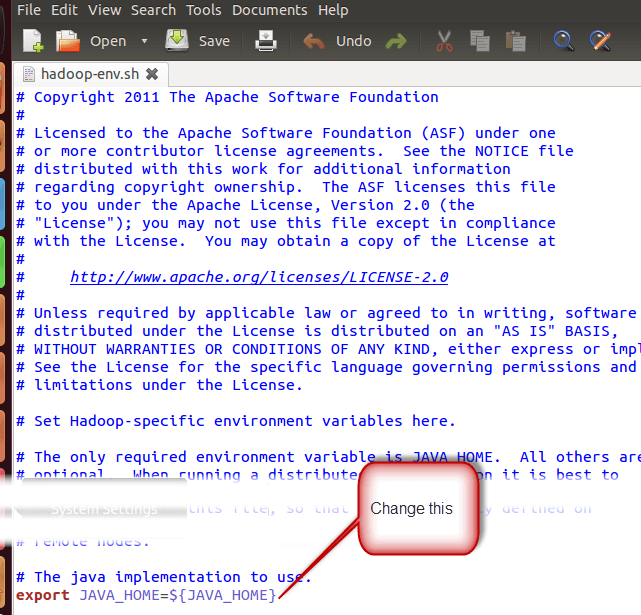
配置后:
配置核心组件文件
$HADOOP_HOME/etc/hadoop/core-site.xml 中有两个参数
- hadoop.tmp.dir - 用于Hadoop的存储数据文件的目录
fs.default.name - 指定默认的文件系统
1.打开文件
1
sudo gedit $HADOOP_HOME/etc/hadoop/core-site.xml
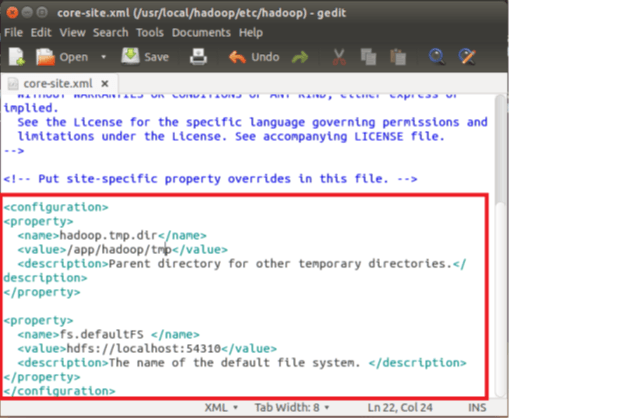
2.复制下面配置到 文件内容的
<configuration>和</configuration>之间1
2
3
4
5
6
7
8
9
10<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/install/hadoop/tmp</value>
<description>Parent directory for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS </name>
<value>hdfs://master:54310</value>
<description>The name of the default file system. </description>
</property>
- 3.移动到目录 $HADOOP_HOME/etc/hadoop
1 | sudo mkdir -p <以上设置中使用的目录路径> |
- 4.授权目录权限
1 | sudo chown -R hadoop:hadoop <在上一步中创建的目录路径> |
配置文件系统
1.打开文件 $HADOOP_HOME/etc/hadoop/hdfs-site.xml
1
sudo gedit $HADOOP_HOME/etc/hadoop/hdfs-site.xml
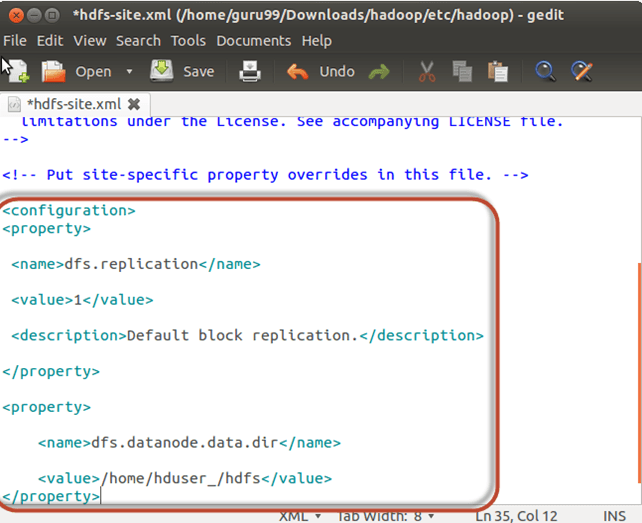
2.复制下面配置到 文件内容的
<configuration>和</configuration>之间1
2
3
4
5
6
7
8
9<property>
<name>dfs.replication</name>
<value>1</value>
<description>Default block replication.</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/install/hadoop/hdfs</value>
</property>
- 3.创建以上设置中指定的目录并授权
1
2
3sudo mkdir -p /hadoop/install/hadoop/hdfs
sudo chown -R hadoop:hadoop /hadoop/install/hadoop/hdfs
sudo chmod 750 /hadoop/install/hadoop/hdfs
配置 Map Reduce
配置环境变量
1.设置HADOOP_HOME路径
1
2
3sudo gedit /etc/profile.d/hadoop.sh # 打开文件
export HADOOP_HOME=<Hadoop的安装路径> # 增加设置环境变量命令
sudo chmod +x /etc/profile.d/hadoop.sh # 脚本增加执行权限2.增加脚本权限,并退出终端界面
1
2
3sudo chmod +x /etc/profile.d/hadoop.sh # 脚本增加执行权限
# 重新登陆使用命令验证变量设置是否生效
echo $HADOOP_HOME
配置MapReduce计算框架文件
1.复制文件 mapred-site.xml 并打开
1
2sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
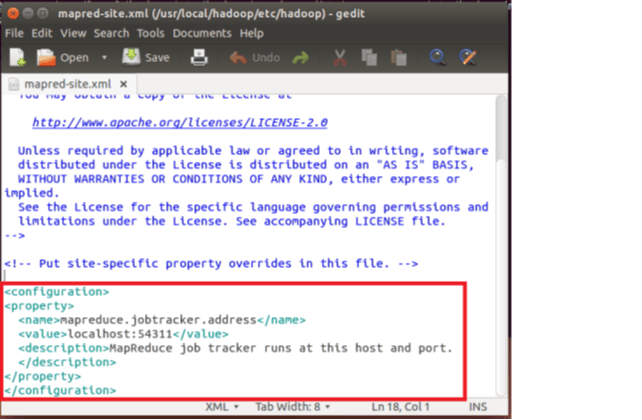
sudo gedit $HADOOP_HOME/etc/hadoop/mapred-site.xml2.复制下面配置到 文件内容的
<configuration>和</configuration>之间1
2
3
4
5
6<property>
<name>mapreduce.jobtracker.address</name>
<value>master:54311</value>
<description>MapReduce job tracker runs at this host and port.
</description>
</property>
配置 yarn-site.xml 文件
1.打开文件 $HADOOP_HOME/etc/hadoop/yarn-site.xml
1
sudo gedit $HADOOP_HOME/etc/hadoop/yarn-site.xml
2.复制下面配置到 文件内容的
<configuration>和</configuration>之间1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
格式化HDFS
1 | $HADOOP_HOME/bin/hdfs namenode -format |
启动Hadoop
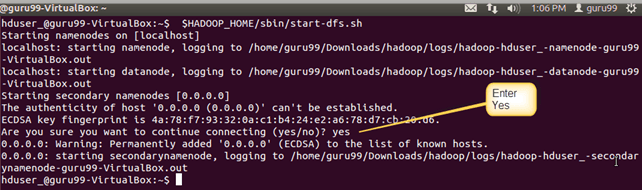
- 1.使用以下命令启动hdfs
1
$HADOOP_HOME/sbin/start-dfs.sh
2.使用以下命令启动yarn
1
$HADOOP_HOME/sbin/start-yarn.sh
3.使用 jps 工具/命令,验证所有与Hadoop相关的进程是否正在运行。如果Hadoop已成功启动,则jps的输出应显示NameNode/NodeManager/ResourceManager/SecondaryNameNode/DataNode。
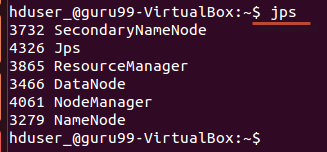
停止Hadoop
1 | $HADOOP_HOME/sbin/stop-dfs.sh |