Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。
本文章主要介绍 Spark 和 在centos环境下如何安装 。
Quick Guide
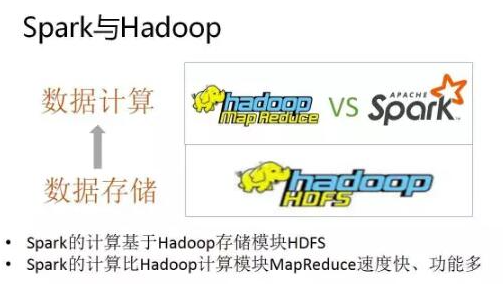
一、Hadoop 和 Spark 的关系
Hadoop有两个核心模块,分布式存储模块HDFS和分布式计算模块Mapreduce
spark本身并没有提供分布式文件系统,因此spark的分析大多依赖于Hadoop的分布式文件系统HDFS
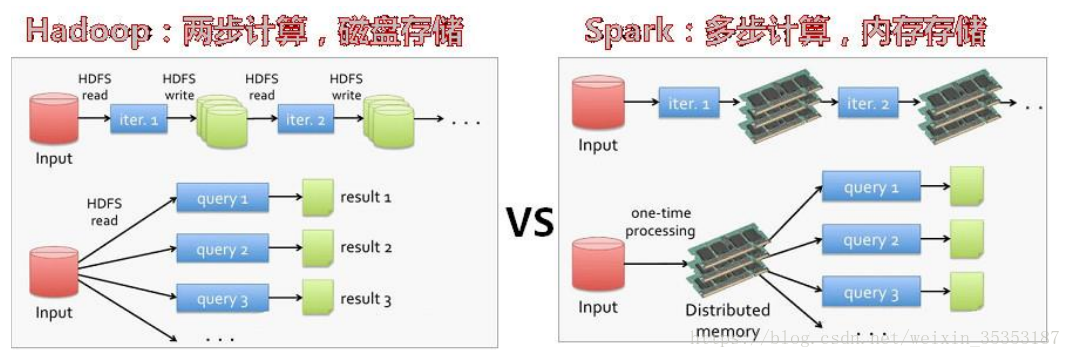
Hadoop的Mapreduce与spark都可以进行数据计算,而相比于Mapreduce,spark的速度更快并且提供的功能更加丰富

二、 Spark 的特点
Spark具有如下几个主要特点:
- 运行速度快:Spark使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍;
- 容易使用:Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程;
- 通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算;
- 运行模式多样:Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
三、Spark 架构
1.Spark生态系统
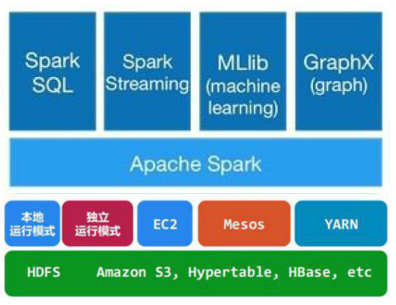
- Spark Core:包含Spark的基本功能,尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
- Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据
- MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
- GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
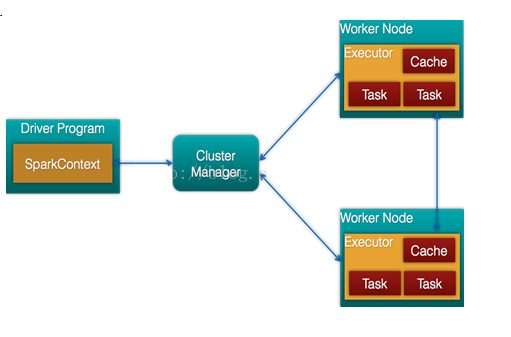
2.架构
3.基本概念
| Term(术语) | Meaning(含义) |
|---|---|
| Cluster manager | 一个外部的用于获取集群上资源的服务。(在standalone模式中即为Master主节点,控制整个集群,监控worker;在YARN模式中为资源管理器。 |
| Driver program | 该进程运行应用的 main() 方法并且创建了 SparkContext。 |
| RDD | 是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型 |
| DAG | 是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系 |
| Application | 用户构建在 Spark 上的程序。由集群上的一个 driver 程序和多个 executor 组成。 |
| Worker node | 任何在集群中可以运行应用代码的节点。 |
| Executor | 一个为了在 worker 节点上的应用而启动的进程,它运行 task 并且将数据保持在内存中或者硬盘存储。每个应用有它自己的 Executor。 |
| Task | 一个将要被发送到 Executor 中的工作单元。 |
| Job | 一个由多个任务组成的并行计算,并且能从 Spark action 中获取响应(例如 save,collect); 您将在 driver 的日志中看到这个术语。 |
| Stage | 每个 Job 被拆分成更小的被称作 stage(阶段)的 task(任务)组,stage 彼此之间是相互依赖的(与 MapReduce 中的 map 和 reduce stage 相似)。您将在 driver 的日志中看到这个术语。 |
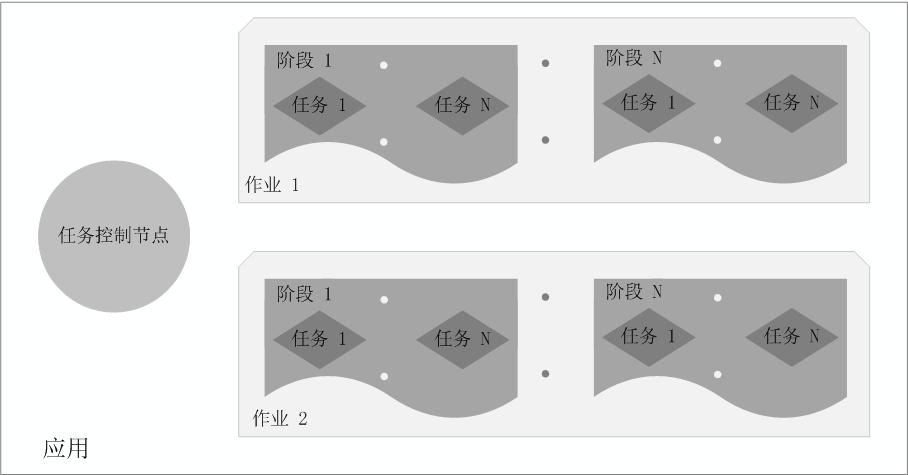
在Spark中,一个应用(Application)由一个任务控制节点(Driver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行任务,运行结束后,执行结果会返回给任务控制节点,或者写到HDFS或者其他数据库中。
4.运行流程
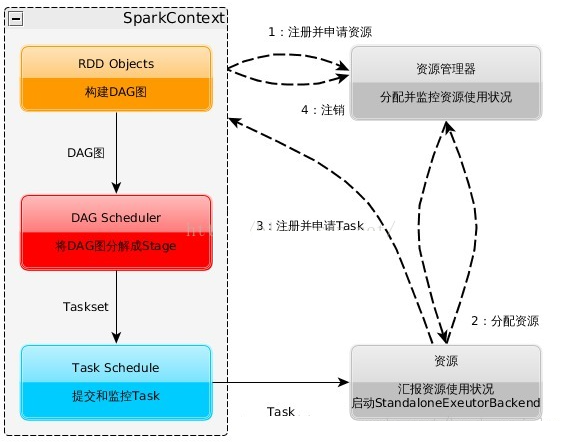
- 构建Spark Application的运行环境,启动SparkContext
- SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend,
- Executor向SparkContext申请Task
- SparkContext将应用程序分发给Executor
- SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行
- Task在Executor上运行,运行完释放所有资源
四、Spark的部署模式
1.standalone模式
与MapReduce1.0框架类似,Spark框架本身也自带了完整的资源调度管理服务,可以独立部署到一个集群中,而不需要依赖其他系统来为其提供资源管理调度服务。在架构的设计上,Spark与MapReduce1.0完全一致,都是由一个Master和若干个Slave构成,并且以槽(slot)作为资源分配单位。不同的是,Spark中的槽不再像MapReduce1.0那样分为Map 槽和Reduce槽,而是只设计了统一的一种槽提供给各种任务来使用。2.Spark on Mesos模式
Mesos是一种资源调度管理框架,可以为运行在它上面的Spark提供服务。Spark on Mesos模式中,Spark程序所需要的各种资源,都由Mesos负责调度。由于Mesos和Spark存在一定的血缘关系,因此,Spark这个框架在进行设计开发的时候,就充分考虑到了对Mesos的充分支持,因此,相对而言,Spark运行在Mesos上,要比运行在YARN上更加灵活、自然。目前,Spark官方推荐采用这种模式,所以,许多公司在实际应用中也采用该模式。3.Spark on YARN模式
Spark可运行于YARN之上,与Hadoop进行统一部署,即“Spark on YARN”,资源管理和调度依赖YARN,分布式存储则依赖HDFS。
五、部署安装
0.前置
- 安装java
- 安装hadoop
1.安装Scala
0.从官网下载安装包到 /hadoop/software
1.解压到指定文件
1
2cd /hadoop/software
tar -zxvf scala-2.11.8.tgz -C /haddop/install2.修改环境变量
1
2
3
4
5vi /etc/profile
# 在末尾追加内容
export SCALA_HOME=/haddop/install/scala-2.11.8
export PATH=$SCALA_HOME/bin:$PATH3.使环境变量生效
1
source /etc/profile
4.检查安装是否成功
1
scala -version
2.安装Spark
0.从官网下载安装包到/hadoop/software
1.解压到指定文件
1
2
3
4cd /hadoop/software
tar -zxvf spark-2.3.3-bin-hadoop2.7.tgz -C /haddop/install
cd /haddop/install
mv spark-2.3.3-bin-hadoop2.7 spark
2.修改环境变量
1
2
3
4
5vi /etc/profile
# 在末尾追加内容
export SPARK_HOME=/hadoop/install/spark
export PATH=$SPARK_HOME/bin:$PATH3.使环境变量生效
1
source /etc/profile
3.设置部署模式
local模式
1
spark-shell
Standalone模式
1.配置文件slaves.template
1
2
3cd /haddop/install/spark/conf
cp slaves.template slaves
vi slaves添加以下内容 slavexx(看节点数量):
1
2
3
4Master
Slave1
Slave2
Slave32.配置spark-env.sh
1
2cp spark-env.sh.template spark-env.sh
vi spark-env.sh添加以下内容 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37# JAVA的路径
export JAVA_HOME=${JAVA_HOMRE}
# SCALA的路径
export SCALA_HOME=${SCALA_HOME}
# HADOOP的路径
export HADOOP_CONF_DIR=${HADOOP_HOME}
# master的ip或host
export SPARK_MASTER_IP=master
# 提交任务的端口
export SPARK_MASTER_PORT=7077
# 浏览器访问master的端口
export SPARK_MASTER_WEBUI_PORT=8080
# 每个worker从节点能够支配的core的个数
export SPARK_WORKER_CORES=2
# 每个worker从节点能够支配的内存数
export SPARK_WORKER_MEMORY=内存大小
#每个worker
export SPARK_WORKER_PORT=7078
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_WORKER_INSTANCES=1
# 每个worker的数据存放
export SPARK_WORKER_DIR=${SPARK_HOME}/data/tmp
# 设定Spark executor的内存大小
export SPARK_EXECUTOR_MEMORY=1G
# 设定Spark executor 使用的cpu的核的数量
export SPARK_EXECUTOR_CORES=13.配置修改Spark-defaults.conf
1
2cp spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf添加以下内容 :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# 设置事件日志为true
spark.eventlog.enabled=true
# 设置记录删除时间
spark.history.fs.cleaner.interval=1d
spark.history.fs.cleaner.maxAge=7d
# 设定事件日志目录
spark.eventlog.dir hdfs://nn/user/spark/history
# 设定Driver的内存大小
spark.driver.memory 1g
# 设定历史操作日志操作保存路径
spark.history.fs.logDirectory hdfs://nn/usr/spark/history
# 设定仓库目录
spark.sql.warehouse.dir /user/spark/warehouse
Yarn模式:在standalone模式的基础上,在客户端的spark-env.sh文件中配置
1
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop