这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop、Storm,以及后来的 Spark,他们都有着各自专注的应用场景。
Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热地掩盖了其他分布式计算的系统身影,例如 Flink在这个时候默默地发展着。在国外一些社区,有很多人将大数据的计算引擎分成了 4 代,当然也有很多人不会认同,我们先姑且这么认为和讨论。
首先第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce。这里大家应该都不会对 MapReduce 陌生,它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
由于这样的弊端,催生了支持 DAG 框架的产生,因此支持 DAG 的框架被划分为第二代计算引擎,如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
本文章主要介绍 Flink 和 在centos环境下如何安装 。
Quick Guide
Flink 介绍
Apache Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink设计为在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
1. 批处理和流处理
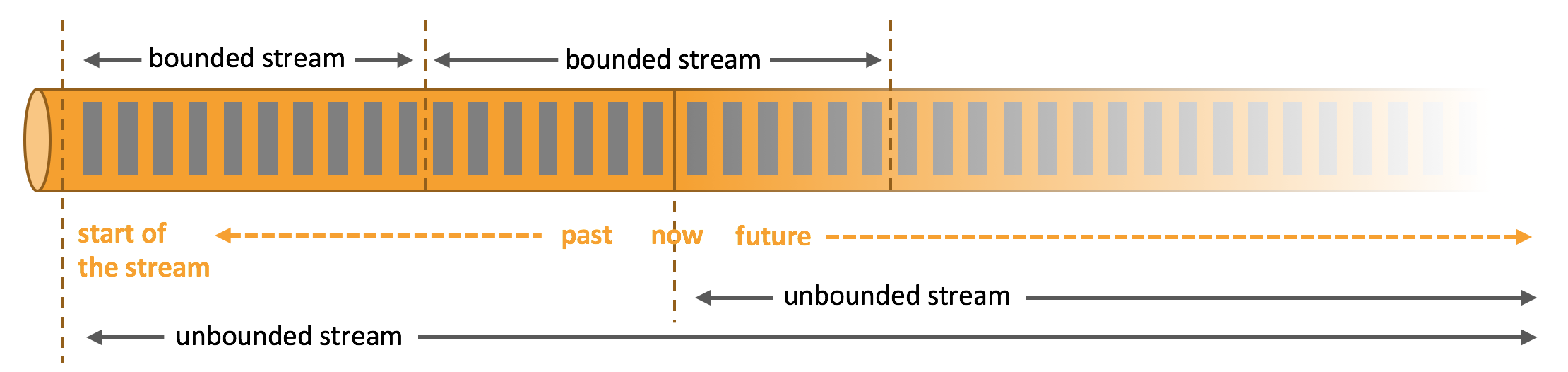
数据集分为有界数据集和无界数据集:
- 有界数据集:有界数据流就是指输入的数据有始有终。例如数据可能是一分钟或者一天的交易数据等等。处理这种有界数据流的方式也被称之为批处理;
- 无界数据集:有界数据流就是指有始无终的数据,数据一旦开始生成就会持续不断的产生新的数据,即数据没有时间边界源源不断(比如日志),处理这种有界数据流的方式也被称之为流处理。
我们一般所说的数据流是指数据集,而流数据则是指数据流中的数据。流处理更复杂,因为需要考虑到数据的顺序错乱和系统容错等。
二、架构的演变
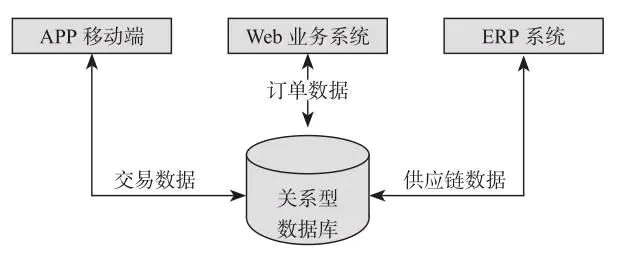
- 1.传统单体数据架构
传统单体数据架构中,数据集中存储,架构分成计算层和存储层。这种架构初期效率很高,但是随着 业务种类越来越多,系统越来越难以维护升级,此外 database 是唯一准确的数据源,每个 application 都需要访问 database 来获取对应的数据,一旦 database 发生改变或者出现问题,将会对整个业务系统产生影响。
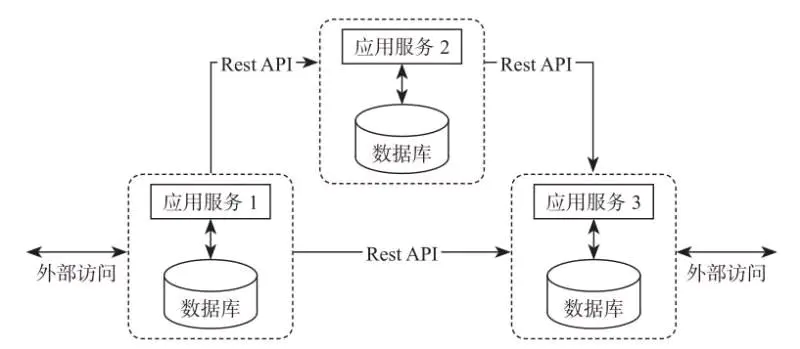
- 2.微服务架构
微服务架构的核心是:1个 application 由多个小的且相互独立的微型服务组成,各服务的开发和发布不存在依赖关系,这样整个系统相比于之前的传统单体数据架构就更加灵活。
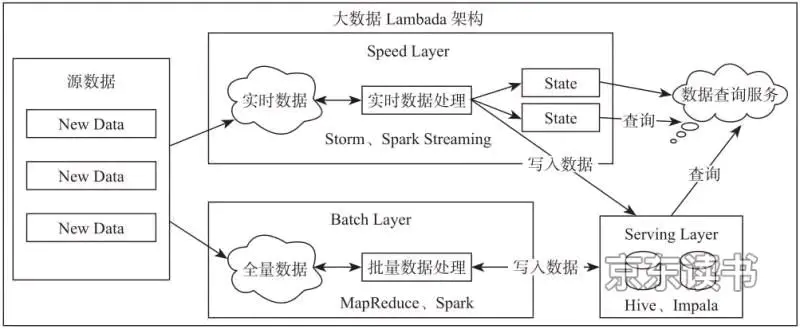
- 3.大数据 lambada 架构
lambada 架构分两种处理途径,Speed layer 负责批处理(比如 Hadoop MapReduce),Batch layer 则负责流处理(比如 Storm)。这种架构存在问题:框架较多会导致平台复杂度高、运维成本高。虽说后面 Spark 框架能够同时支持批计算和流计算,但是Spark Streaming 的流计算本质上依旧是微批处理并非实时流计算。
4.Flink
相比于 Spark Streaming的微批处理模式,Flink 通过 Google Dataflow 模型实现了实时流计算框架,将有界数据集转换成无界数据集统一进行流式处理。Flink 具有如下优势:
- 流处理特性
- 高吞吐、低延时、高性能;
- 支持事件时间(Event Time)概念:大多数框架中窗口计算采用系统时间(即Event 到达计算框架是 host 的当前时刻),而 Flink 则能够基于事件时间(即 Event 本身产生的时刻,当然也可以基于其他类型)语义进行窗口计算。基于事件驱动的优势在于即使 Event 到达的顺序乱了,框架也能够准确知道事件的时序性;
- 支持高度灵活的窗口计算操作:流处理中,数据就像stream 一样源源不断地进入到框架中进行处理。有时需要通过窗口的方式对 stream 进行一定范围内的聚合计算。比如统计某网页在过去1分钟内的点击数。这种情况下就需要定义一个窗口,收集最近1分钟内的数据,并对这些数据进行计算。Flink 的窗口计算包括Time、Count、Session、Data-driven 等类型的窗口操作,可以灵活使用触发条件定制化来达到复杂的计算需求;
- 基于轻量级分布式快照(Snapshot)实现容错机制:Flink 可以分布运行在多达上千个节点上,将一个大型计算任务流程分解成多个小的计算stage,再分布到节点上并行处理。任务执行过程中,分布式Snapshot(通过 Save points 实现) 的 Checkpoints能够将状态信息进行持久化到存储介质中(比如磁盘),一旦某些任务出现异常,就能够从Checkpoints 中恢复任务,从而确保数据处理过程中的一致性;
- 基于 JVM 实现独立的内存管理:大数据处理中内存管理是非常重要的部分,Flink 实现了自身管理内存的机制,且通过 序列化/反序列化方法将所有数据对象转换成二进制存储在内存中,降低数据存储 size 的同时,更高效地利用内存,降低 JVM GC 对框架性能的影响。
- API支持
- 对Streaming数据类应用,提供DataStream API
- 对批处理类应用,提供DataSet API(支持Java/Scala)
- Libraries支持
- 支持机器学习(FlinkML)
- 支持图分析(Gelly)
- 支持关系数据处理(Table)
- 支持复杂事件处理(CEP)
- 整合支持
- 支持Flink on YARN
- 支持HDFS
- 支持来自Kafka的输入数据
- 支持Apache HBase
- 支持Hadoop程序
- 支持Tachyon
- 支持ElasticSearch
- 支持RabbitMQ
- 支持Apache Storm
- 支持S3
- 支持XtreemFS
- 生态圈
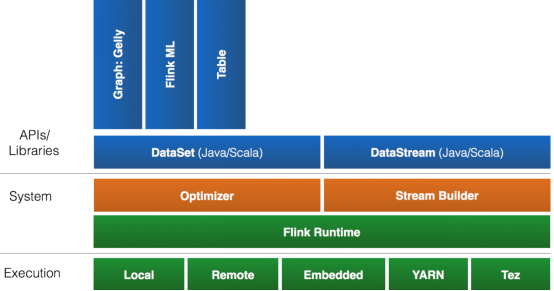
- 流处理特性
三、Flink应用场景
- 实时智能推荐;
- 复杂事件处理;
- 实时欺诈检测;
- 实时数仓与 ETL;
- 流数据分析;
- 实时报表分析。
四、Flink运行架构
1.术语
- Client:用来提交任务给 JobManage
- JobManager(指挥者,JVM 进程):JobManagers是在Flink主服务器中运行的组件之一。用于任务调度(分发任务给 TaskManager 去执行)、协调检查点和协调故障恢复;
- Task:基本的工作单元,由Flink的运行时执行任务。任务是封装运算符或运算符链的一个并行实例。
- TaskManager(一个对应一个 JVM 进程):worker节点执行任务的数据流,缓冲器以及交换数据流;
- TaskManager Slots :用来分割资源,控制worker可以接受多少个任务。
- Akka:所有组件之间的通信,包括任务状态、Checkpoint 触发等消息。
- Netty:数据的传输
- Parallelism: 并行度
2.任务提交和处理流程
- Client 将 application(任务) 提交到 Flink cluster,并于 JobManager 创建 Akka 连接,然后将application 提交给 JobManager;提交方式包括:
- CLI(类似 Spark-submit);
- Flink WebUI 提交;
- 应用程序中指定 JobManager 的 RPC 网络端口构建 Execution Environment 提交 Flink 应用;
- 根据 Flink 集群中 TaskManager 上 TaskSlot 的使用情况,为提交的 application `分配 TaskSlots 资源 并命令 TaskManager 启动 application;
- TaskManager 从 JobManager 接收计算任务,然后使用 Slot 资源启动 application,建立数据接入的网络连接、接收数据、处理数据;各 TaskManaer 之间的数据交互通过数据流进行;
- JobManager 和 TaskManager 之间通过 Actor System 进行通信,application 的执行进度会发送给 client 端;在执行 application 过程中,JobManager 会触发 Checkpoints 操作,每个 TaskManager 收到 Checkpoints 触发指令后,会完成 Checkpoint 操作;
- application 执行完成后,执行状态将会反馈给 client 端,并释放掉 TaskManager 中的资源供下一次提交任务使用。
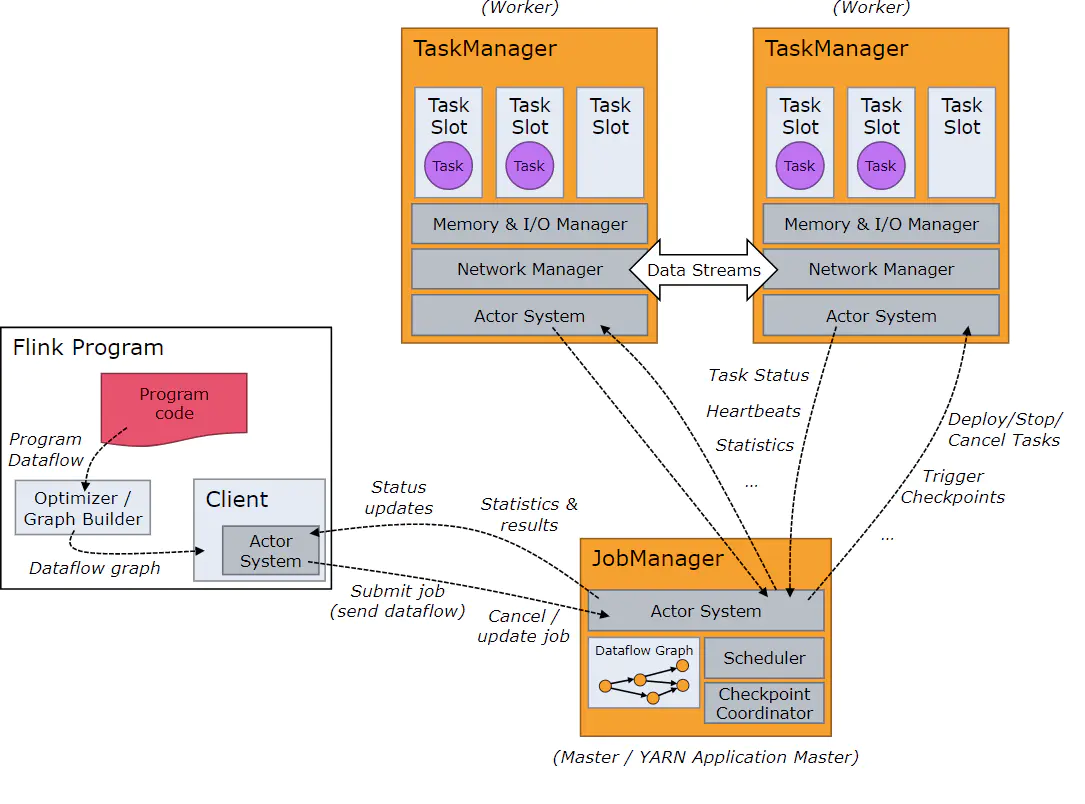
五、Flink中的编程模型
1.编程模型
在Flink,编程模型的抽象层级主要分为以下4种,越往下抽象度越低,编程越复杂,灵活度越高。
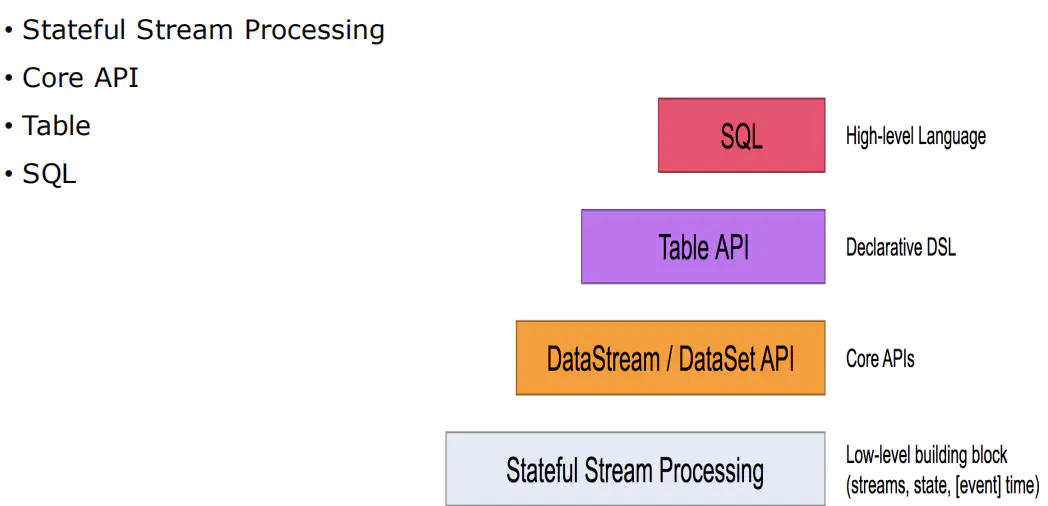
这4层中,一般用于开发的是第二层,即DataStrem/DataSetAPI。用户可以使用DataStream API处理无界数据流,使用DataSet API处理有界数据流。同时这两个API都提供了各种各样的接口来处理数据。例如常见的map、filter、flatMap等等,而且支持python,scala,java等编程语言,后面的demo主要以scala为主。
- Stateful Stream Processiing
- 位于最底层,是core API的底层实现
- process Function
- 利用低阶,构建一些新组件(比如:利用其定时做一定情况下的匹配和缓存)
- 灵活度高,但看法比较复杂
- Core APIS
- DataStream 流式处理
- DataSet 批量处理
- Table & SQL
- SQL构建在Table之上,都需要构建Table环境。
- 不同类型的Table构建不同的Table环境。
- Table可以与DataStream或者DataSet进行相互转换。
- Streaming SQL不同存储的SQL, 最终会转化为流式执行计划
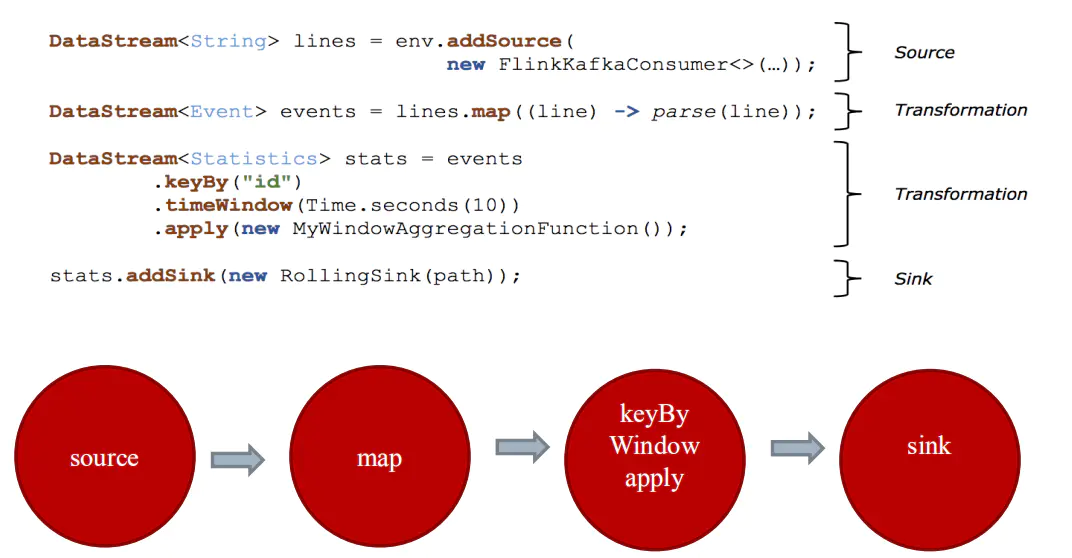
2.构建流程
- 构建计算环境(决定采用哪种计算执行方式)
- 创建Source(可以多个数据源)
- 对数据进行不同方式的转换(提供丰富的算子)
- 对结果的数据进行Sink(可以输出到多个地方)
六、安装
- 0.前置
- 安装java
- Hadoop
- scala
1.Flink的下载::从官网选择对应Flink版本下载
1
2cd /hadoop/software
wget http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink/flink-1.11.1/flink-1.11.1-bin-scala_2.11.tgz2.解压安装:
1
2
3tar -zvxf flink-1.11.1-bin-scala_2.11.tgz -C /hadoop/install
cd /hadoop/install
mv flink-1.11.1-bin-scala_2.11 flink3.配置环境变量:
1
2
3
4
5vi /etc/profile
# 追加内容:
export FLINK_HOME=/hadoop/install/flink
export PATH=$PATH:$FLINK_HOME/bin4.使环境变量生效
1
source /etc/profile
七、部署
Flink 有三种部署模式,分别是 Local、Standalone Cluster( 依赖于 Zookeeper 来实现 JobManager 的 HA ) 和 Yarn Cluster( 依靠 Yarn 本身来对 JobManager 做 HA )。
1.Local 模式
对于 Local 模式来说,JobManager 和 TaskManager 会公用一个 JVM 来完成 Workload。如果要验证一个简单的应用,Local 模式是最方便的。
1 | start-local.sh |
2.Standalone 模式
参考入门教程
1.部署规划
| 节点名称 | master | worker | zookeeper |
| ——– | —— | —— | ——— |
| master | master | | zookeeper |
| node1 | | worker | zookeeper |
| node2 | | worker | zookeeper |
| node3 | | worker | zookeeper |2.修改配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22cd flink/conf
# 1.修改masters
vi masters
修改内容如下:
master:8081
# 2.修改slaves
vi slaves
修改内容如下:
node1
node2
node3
# 3.修改flink-conf.yaml
vi flink-conf.yaml
修改内容如下:
taskmanager.numberOfTaskSlots:2
jobmanager.rpc.address: master可选配置:
1
2
3
4
5每个JobManager(jobmanager.heap.mb)的可用内存量
每个TaskManager(taskmanager.heap.mb)的可用内存量
每台机器的可用CPU数量(taskmanager.numberOfTaskSlots)
集群中的CPU总数(parallelism.default)
临时目录(taskmanager.tmp.dirs
- 3.拷贝安装包到各节点
1
2
3scp -r flink/ hadoop@node1:`pwd`
scp -r flink/ hadoop@node2:`pwd`
scp -r flink/ hadoop@node3:`pwd`
4.启动flink
1
start-cluster.sh
5.WebUI查看:访问http://master:8081
注:这里只是集群模式而已,在实际场景中,我们一般需要配置为HA,防止Jobmanager突然挂掉,导致整个集群或者任务执行失败的情况发生。下面介绍一下Standalone HA模式的搭建安装
3.Standalone HA模式
依赖于 Zookeeper 来实现 JobManager 的 HA。在 Zookeeper 的帮助下,一个 Standalone 的 Flink 集群会同时有多个活着的 JobManager,其中只有一个处于工作状态,其他处于 Standby 状态。当工作中的 JobManager 失去连接后(如宕机或 Crash),Zookeeper 会从 Standby 中选举新的 JobManager 来接管 Flink 集群。
1.更改conf/flink-conf.yaml配置文件
1
2
3
4
5
6
7
8
9#jobmanager.rpc.address: master
high-availability:zookeeper #指定高可用模式(必须)
high-availability.zookeeper.quorum:master:2181,node1:2181,node2:2181,node3:2181 # ZooKeeper仲裁是ZooKeeper服务器的复制组,它提供分布式协调服务(必须)
high-availability.storageDir:hdfs:///flink/ha/ #JobManager元数据保存在文件系统storageDir中,只有指向此状态的指针存储在ZooKeeper中(必须)
high-availability.zookeeper.path.root:/flink #根ZooKeeper节点,在该节点下放置所有集群节点(推荐)
high-availability.cluster-id:/flinkCluster #自定义集群(推荐)
state.backend: filesystem
state.checkpoints.dir: hdfs:///flink/checkpoints
state.savepoints.dir: hdfs:///flink/checkpoints2.修改conf/masters
1
2master:8081
node1:80813.分发配置文件,将刚刚修改的配置文件 masters 和 flink-conf.yaml 分发至另外三个节点。
- 4.重启flink集群:start-cluster.sh
4.Yarn Cluster
Yarn Cluaster 模式来说,Flink 就要依靠 Yarn 本身来对 JobManager 做 HA 了。
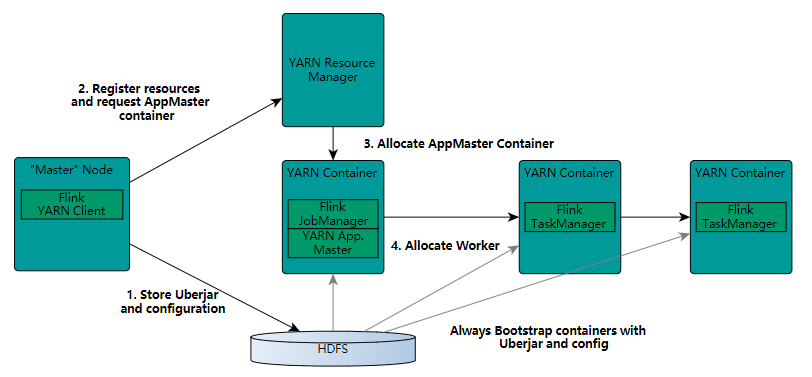
在图中可以看出,Flink 与 Yarn 的关系与 MapReduce 和 Yarn 的关系是一样的。Flink 通过 Yarn 的接口实现了自己的 App Master。当在 Yarn 中部署了 Flink,Yarn 就会用自己的 Container 来启动 Flink 的 JobManager(也就是 App Master)和 TaskManager。
启动新的Flink YARN会话时,客户端首先检查所请求的资源(容器和内存)是否可用。之后,它将包含Flink和配置的jar上传到HDFS(步骤1)。
客户端的下一步是请求(步骤2)YARN容器以启动ApplicationMaster(步骤3)。由于客户端将配置和jar文件注册为容器的资源,因此在该特定机器上运行的YARN的NodeManager将负责准备容器(例如,下载文件)。完成后,将启动ApplicationMaster(AM)。
该JobManager和AM在同一容器中运行。一旦它们成功启动,AM就知道JobManager(它自己的主机)的地址。它正在为TaskManagers生成一个新的Flink配置文件(以便它们可以连接到JobManager)。该文件也上传到HDFS。此外,AM容器还提供Flink的Web界面。YARN代码分配的所有端口都是临时端口。这允许用户并行执行多个Flink YARN会话。
之后,AM开始为Flink的TaskManagers分配容器,这将从HDFS下载jar文件和修改后的配置。完成这些步骤后,即可建立Flink并准备接受作业。
1.修改环境变量
1
export HADOOP_CONF_DIR=/hadoop/install/hadoop/etc/hadoop
2.部署启动
1
yarn-session.sh -d -s 2 -tm 800 -n 2
1
2
3
4-n : TaskManager的数量,相当于executor的数量
-s : 每个JobManager的core的数量,executor-cores。建议将slot的数量设置每台机器的处理器数量
-tm : 每个TaskManager的内存大小,executor-memory
-jm : JobManager的内存大小,driver-memory3.Yarn 模式的HA:修改 yarn-site.xml文件($HADOOP_HOME/etc/hadoop/yarn-site.xml)的 应用最大尝试次数(max-attempts)
1
2
3
4
5<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>The maximum number of application master execution attempts</description>
</property>
More info: flink