Elasticsearch( 数据搜索引擎持久化 )、Logstash ( 数据收集 ) 、 Kibana ( 数据分析工具 )的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
本文章主要介绍 Elasticsearch 的入门知识。
Quick Guide
Elasticsearch是一个开源的分布式. RESTful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。
Lucene 可以说是当下最先进. 高性能. 全功能的搜索引擎库——无论是开源还是私有,但它也仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 把 Lucene 集成到应用程序中,使用比较复杂。
为了解决Lucene使用时的繁复性,于是Elasticsearch便应运而生。它使用 Java 对Lucene 做了一层封装,提供了一套简单一致的 RESTful API 来帮助我们实现存储和检索。
一、基本概念
Elasticsearch 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
| 关系型数据库(MySQL) | Elasticsearch |
|---|---|
| 数据库database | 索引 index |
| 表 table | 类型 type |
| 数据行 row | 文档 document |
| 数据列 column | 字段 field |
Elasticsearch 的文件存储是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
1 | { |
用Mysql这样的数据库存储就会容易想到建立一张User表,有name、sex等字段,在 Elasticsearch 里这就是一个属于User的类型,各种各样的类型存在于一个索引当中。
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。Elasticsearch的交互,可以使用Java API,也可以直接使用HTTP的Restful API方式。
1 | # 插入一条记录,可以简单发送一个HTTP的请求 |
更新、查询也是类似这样的操作,具体操作手册可以参考 Elasticsearch权威指南
二、Elasticsearch 模块结构
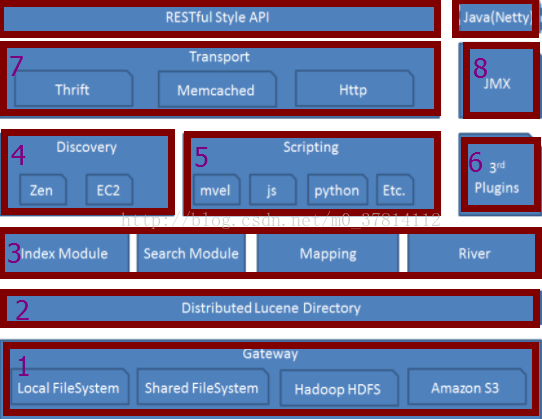
- 第一层:Gateway层:Elasticsearch 索引的持久化存储方式 。 ElasticSearch 默认先把索引存储在内存中,然后当内存满的时候,再持久化到Gateway里。当ES集群关闭或重启的时候,它就会从Gateway里去读取索引数据。比如LocalFileSystem和HDFS、AS3等。
- 第二层:Distributed lucene directory层: Lucene里的一些列索引文件组成的目录。它负责管理这些索引文件。包括数据的读取、写入,以及索引的添加和合并等。
- 第三层:Elasticsearch 对数据的加工处理方式,mapping:定义索引下面type字段的处理规则,比如:索引如何建立数据类型等等,相当于关系型数据里面的schema。River是一个运行在 Elasticsearch 集群内部的一个插件,主要是用来从外部获取异构数据,然后在 Elasticsearch 里创建索引,常见的插件有rabbitmq. twitter river。
- 第四层:是 Elasticsearch 自动发现节点的机制。Zen是用来实现节点自动发现,还有master节点选取用的,假如maste出现了故障,不能工作了,那么其它节点会自动选举,然后产生一个新的master。Elasticsearch 是基于P2P的系统,它首先头通过广播机制寻找存在的节点,然后再通过多播协议来进行节点间的通信,同时也支持点对点交互。
- 第五层:是 Elasticsearch 的脚本执行功能,有了这个功能很方便的对查询出来的数据进行加工处理,脚本类型:mvel. js. python等。
- 第六层:3rd plugins:意思是 Elasticsearch 支持安装很多第三方插件。
- 第七层:是 Elasticsearch 的交互方式,支持三种协议:thrift. memcached. http,其中 Elasticsearch 是默认用http协议传输的。
- Restful Style API:是 Elasticsearch 的API支持模式,现在这个RESTFUL这样的API接口的标准是非常流行的
- java(Netty):Elasticsearch 采用了java语言,同时java语言也是对 Elasticsearch 支持度最好的语言,因为这个lucene是基于java开发的。
三、安装部署
0.安装 java 8 以上版本(包含)
1.下载安装
1
2
3wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.1.zip
unzip elasticsearch-5.5.1.zip
cd elasticsearch-5.5.1/2.启动 Elasticsearch
1 | ./bin/elasticsearch |
如果这时报错”max virtual memory areas vm.maxmapcount [65530] is too low”,要运行命令( sudo sysctl -w vm.max_map_count=262144 )。
- 3.验证
1 | curl localhost:9200 |
四、使用
Elasticsearch提供了多种交互使用方式,包括Java API和RESTful API 。现在主要介绍RESTful API ,所有其他语言可以使用RESTful API 通过端口 9200 和 Elasticsearch 进行通信,你可以用你最喜爱的 web 客户端访问 Elasticsearch ,也可以使用 curl 命令来和 Elasticsearch 交互。
一个Elasticsearch请求和任何 HTTP 请求一样,都由若干相同的部件组成:
1 | curl -X <VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>' |
返回的数据格式为JSON,因为Elasticsearch中的文档以JSON格式储存。其中被 < > 标记的部件:
| 部件 | 说明 |
|---|---|
| VERB | 适当的 HTTP 方法 或 谓词 : GET、 POST、 PUT、 HEAD 或者 DELETE。 |
| PROTOCOL | http 或者 https(如果你在 Elasticsearch 前面有一个 https 代理) |
| HOST | Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。 |
| PORT | 运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。 |
| PATH | API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm 。 |
| QUERY_STRING | 任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读) |
| BODY | 一个 JSON 格式的请求体 (如果请求需要的话) |
1.基本操作
1.插入数据
1
2
3
4
5curl -X PUT 'localhost:9200/<index_name>/<type_name>/<id>' -d '
{
"user": "xiaoming",
"position": "engineer"
}'2.删除数据
1 | curl -X DELETE 'localhost:9200/<index_name>/<type_name>/<id>' |
3.修改数据(使用插入方式也可以修改数据)
1
2
3
4
5curl -X POST 'localhost:9200/<index_name>/<type_name>/<id>/_update' -d '
{
"user": "daming",
"position": "engineer"
}'4.查询数据
1 | # pretty 代表易读格式 |
2.高级查询
1.返回所有记录
1
curl -X GET 'localhost:9200/<index_name>/<type_name>/_search'
2.条件搜索
1 | # 查询user等于daming的记录,每次从位置1开始(默认是从位置0开始),只返回一条结果。 |
1 | # 查询user等于daming或者xiaoming的记录 |
1 | # 查询user等于daming且position等于engineer的记录 |
More info: ElasticSearch 官方手册