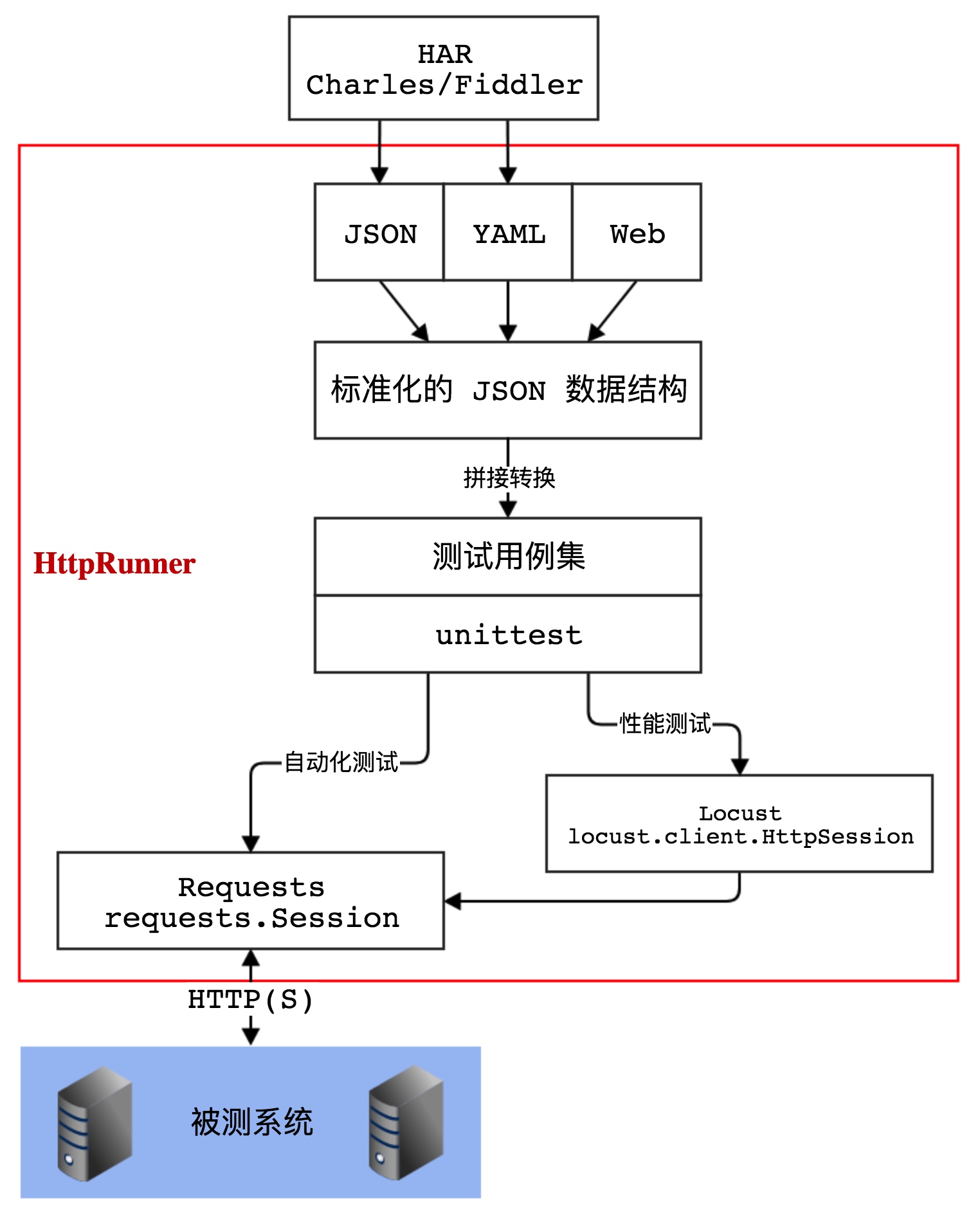
HttpRunner 是一款面向 HTTP(S) 协议的通用测试框架,只需编写维护一份 YAML/JSON 脚本,即可实现自动化测试、性能测试、线上监控、持续集成等多种测试需求。本文章介绍在Windows7如何安装和使用HttpRunner。
Quick Guide
安装
1.使用pip安装
1
pip install httprunner
2.验证安装
1
hrun -V
基本使用
1.新建测试项目
1
hrun --startproject NewApiTest
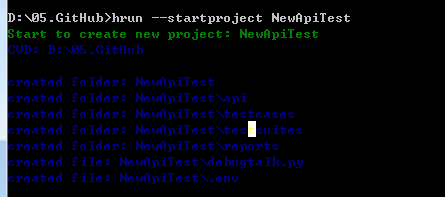
- 2.目录结构说明
- debugtalk.py:该文件所在目录将作为项目工程的根目录,api 文件夹都必须与其放置在相同目录
- api 文件夹:存储接口定义描述
- reports 文件夹:存储 HTML 测试报告
- testcases 文件夹(非必须):存储测试用例,文件夹也可以使用其它名称
- testsuite 文件夹(非必须):测试测试场景,文件夹也可以使用其它名称
- 3.文件类型说明
- YAML/JSON(必须):测试用例文件,存储接口测试相关信息
- debugtalk.py(可选):存储项目中逻辑运算辅助函数
- 该文件存在时,将作为项目根目录定位标记,其所在目录即被视为项目工程根目录
- 该文件不存在时,运行测试的所在路径(CWD)将被视为项目工程根目录
- 测试用例文件中的相对路径(例如.csv)均需基于项目工程根目录
- 运行测试后,测试报告文件夹(reports)会生成在项目工程根目录
- .env(可选):存储项目环境变量,通常用于存储项目敏感信息
- .csv(可选):项目数据文件,用于进行数据驱动
- reports:默认生成测试报告的存储文件夹
- 4.测试用例结构
- 测试用例集(testsuite):对应一个文件夹,包含单个或多个测试用例(YAML/JSON)文件
- 测试用例(testcase):对应一个 YAML/JSON 文件,包含单个或多个测试步骤
- 测试步骤(teststep):对应 YAML/JSON 文件中的一个 test,描述单次接口测试的全部内容,包括发起接口请求、解析响应结果、校验结果等
5.测试用例文件结构(YAML/JSON)
- config:作为整个测试用例的全局配置项
- test:对应单个测试步骤(teststep),测试用例存在顺序关系,运行时将从前往后依次运行各个测试步骤。各个测试步骤(test)的变量空间相互独立,互不影响。需在多个测试步骤(test)中传递参数值,则需要使用 extract 关键字,并且只能从前往后传递。
- 若某变量在 config 中定义了,在某 test 中没有定义,则该 test 会继承该变量
- 若某变量在 config 和某 test 中都定义了,则该 test 中使用自己定义的变量值
1
2
3
4
5
6
7
8
9
10
11[
{
"config": {...}
},
{
"test": {...}
},
{
"test": {...}
}
]config参数说明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23"config": {
"name": "testcase description",
"parameters": [
{"user_agent": ["iOS/10.1", "iOS/10.2", "iOS/10.3"]},
{"app_version": "${P(app_version.csv)}"},
{"os_platform": "${get_os_platform()}"}
],
"variables": [
{"user_agent": "iOS/10.3"},
{"device_sn": "${gen_random_string(15)}"},
{"os_platform": "ios"}
],
"request": {
"base_url": "http://127.0.0.1:5000",
"headers": {
"Content-Type": "application/json",
"device_sn": "$device_sn"
}
},
"output": [
"token"
]
}
| Key | required | format | descrption |
|---|---|---|---|
| name | Yes | string | 测试用例的名称,在测试报告中将作为标题 |
| variables | No | list of dict | 定义的全局变量,作用域为整个用例 |
| parameters | No | list of dict | 全局参数,用于实现数据化驱动,作用域为整个用例 |
| request | No | dict | request 的公共参数,作用域为整个用例;常用参数包括 base_url 和 headers |
| base_url | No | string | 测试用例请求 URL 的公共 host,指定该参数后,test 中的 url 可以只描述 path 部分 |
| headers | No | dict | request 中 headers 的公共参数,作用域为整个用例 |
| output | No | list | 整个用例输出的参数列表,可输出的参数包括公共的 variable 和 extract 的参数; 在 log-level 为 debug 模式下,会在 terminal 中打印出参数内容 |
test参数说明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25"test": {
"name": "get token with $user_agent, $os_platform, $app_version",
"request": {
"url": "/api/get-token",
"method": "POST",
"headers": {
"app_version": "$app_version",
"os_platform": "$os_platform",
"user_agent": "$user_agent"
},
"json": {
"sign": "${get_sign($user_agent, $device_sn, $os_platform, $app_version)}"
},
"extract": [
{"token": "content.token"}
],
"validate": [
{"eq": ["status_code", 200]},
{"eq": ["headers.Content-Type", "application/json"]},
{"eq": ["content.success", true]}
],
"setup_hooks": [],
"teardown_hooks": []
}
}
| Key | required | format | descrption |
|---|---|---|---|
| name | Yes | string | 测试步骤的名称,在测试报告中将作为测试步骤的名称 |
| request | Yes | dict | HTTP 请求的详细内容;可用参数详见 python-requests 官方文档 |
| variables | No | list of dict | 测试步骤中定义的变量,作用域为当前测试步骤 |
| extract | No | list | 从当前 HTTP 请求的响应结果中提取参数,并保存到参数变量中(例如token),后续测试用例可通过$token的形式进行引用 |
| validate | No | list | 测试用例中定义的结果校验项,作用域为当前测试用例,用于实现对当前测试用例运行结果的校验 |
| setup_hooks | No | list | 在 HTTP 请求发送前执行 hook 函数,主要用于准备工作 |
| teardown_hooks | No | list | 在 HTTP 请求发送后执行 hook 函数,主要用户测试后的清理工作 |
6.创建测试用例文件
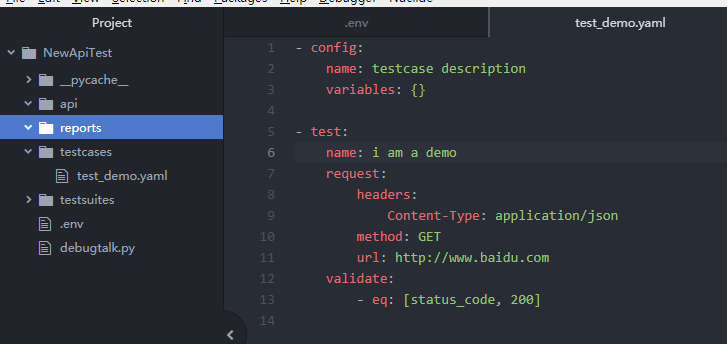
7.运行
1
hrun test_demo.yaml
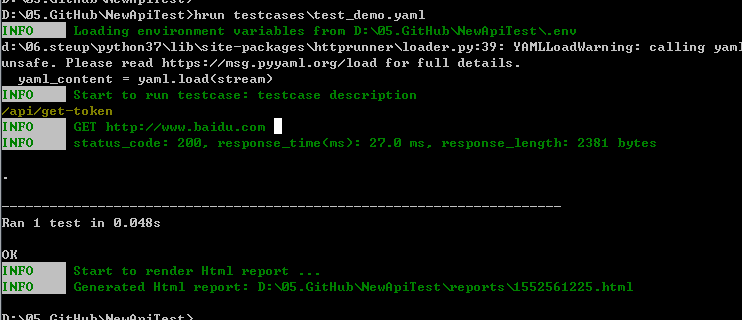
8.报告
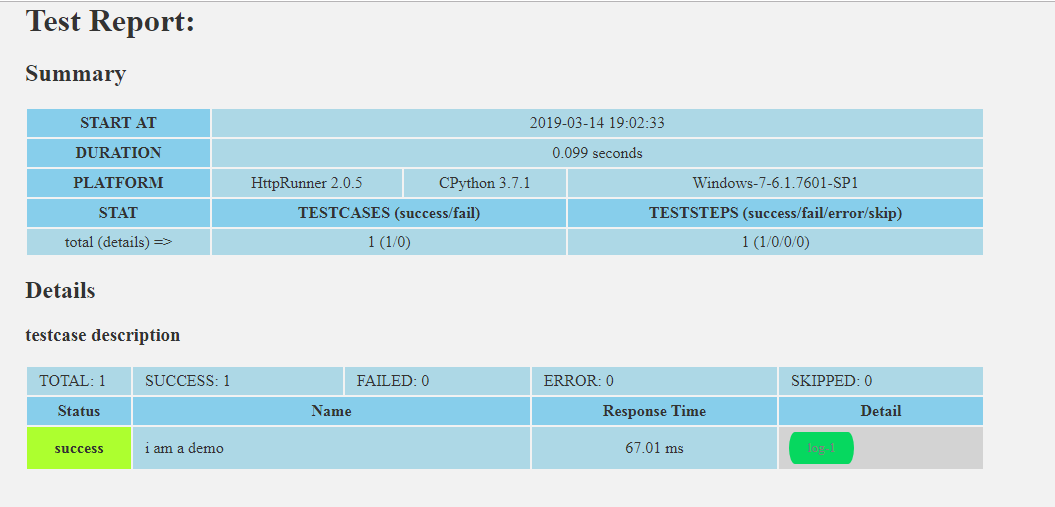
HttpRunnerManager
HttpRunnerManager是基于HttpRunner的接口自动化测试平台,该工具是对 HttpRunner的包装和Web图形化, 另外还增加了一些新概念(项目/模块)用来组织用例
- 1.前置
- 安装mysql(推荐5.7+),并设置为utf-8编码,创建相应HttpRunner数据库,设置好相应用户名、密码,启动mysql
- 安装rabbitmq,需要先安装erlang
2.下载
1
git clone https://github.com/HttpRunner/HttpRunnerManager.git
3.修改配置
打开HttpRunnerManager/HttpRunnerManager/settings.py配置对应mysql和rabbitmq信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42# 修改DATABASES字典为创建的mysql数据库信息和邮件发送账号
if DEBUG:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'HttpRunnerManager', # 新建数据库名
'USER': 'root', # 数据库登录名
'PASSWORD': '', # 数据库登录密码
'HOST': '127.0.0.1', # 数据库所在服务器ip地址
'PORT': '3306', # 监听端口 默认3306即可
}
}
STATICFILES_DIRS = (
os.path.join(BASE_DIR, 'static'), # 静态文件额外目录
)
else:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'HttpRunnerManager', # 新建数据库名
'USER': 'root', # 数据库登录名
'PASSWORD': '', # 数据库登录密码
'HOST': '127.0.0.1', # 数据库所在服务器ip地址
'PORT': '3306', # 监听端口 默认3306即可
}
}
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
# 修改worker配置为搭建rabbitmq的信息
djcelery.setup_loader()
CELERY_ENABLE_UTC = True
CELERY_TIMEZONE = 'Asia/Shanghai'
BROKER_URL = 'amqp://guest:guest@127.0.0.1:5672//' # 127.0.0.1即为rabbitmq-server所在服务器ip地址
CELERYBEAT_SCHEDULER = 'djcelery.schedulers.DatabaseScheduler'
CELERY_RESULT_BACKEND = 'djcelery.backends.database:DatabaseBackend'
CELERY_ACCEPT_CONTENT = ['application/json']
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
CELERY_TASK_RESULT_EXPIRES = 7200 # celery任务执行结果的超时时间,
CELERYD_CONCURRENCY = 10 # celery worker的并发数 也是命令行-c指定的数目 根据服务器配置实际更改 默认10
CELERYD_MAX_TASKS_PER_CHILD = 100 # 每个worker执行了多少任务就会死掉,我建议数量可以大一些,默认1004.安装依赖
1
pip install -r requirements.txt
5.生成表结构
切换到HttpRunnerManager目录 生成数据库迁移脚本,并生成表结构
1
2python manage.py makemigrations ApiManager #生成数据迁移脚本
python manage.py migrate #应用到db生成数据表6.创建用户
创建超级用户,用户后台管理数据库,并按提示输入相应用户名,密码,邮箱。 如不需用,可跳过此步骤
1
python manage.py createsuperuser
7.启动服务
1
python manage.py runserver 0.0.0.0:8000
8.访问
- 注册和登录:浏览器输入 http://127.0.0.1:8000/api/register/ ,平台的使用可以参考新手入门指导
- 运维:浏览器输入 http://127.0.0.1:8000/admin/ 输入之前创建的超级用户名、密码,登录后台运维管理系统,可后台管理数据
性能测试
httprunner可以复用python的开源测试框架locust,locust的安装与使用可以看 这里 ,使用locust对yaml/json用例文件中的接口进行压测
1
locusts -f D://testcases//test_demo.yaml

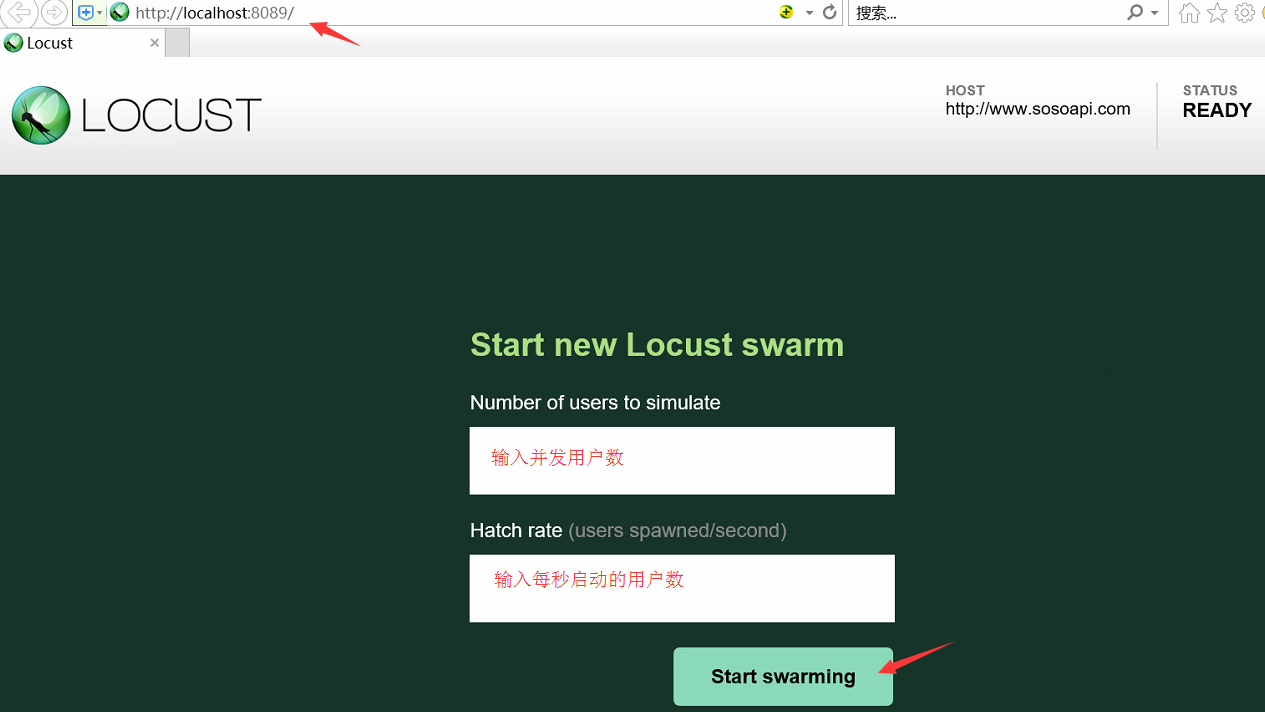
web监控器启动成功,我们点击转到locust的web页面,配置压测参数:
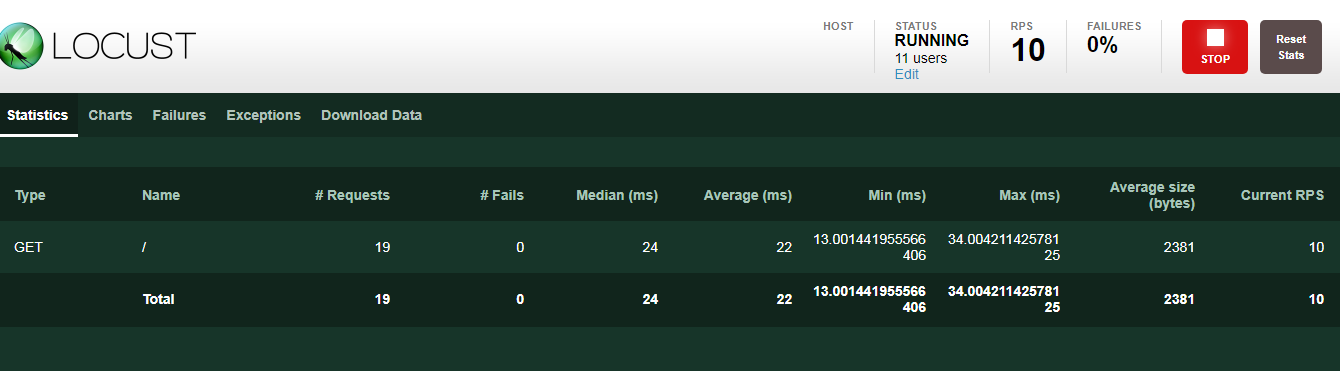
观察结果
More info: 中文文档